rzaimx
2019-03-02 23:02:30
原证
python爬取前程无忧招聘网站数据及可视化分析
项目描述
从前程无忧招聘网站上进行网页抓取,提取各项数据,数据包含多个维度,分别是城市、岗位名称、公司名字、公司规模、公司类型、经验要求、学历要求、专业要求、福利待遇和所属行业等。对爬取的数据进行数据清洗及标准化后,实现数据分析和可视化。最后实践apriori算法,进行频繁项集提取及关联分析。
运行环境
python3.7 PyCharm
项目技术(必填)
python爬虫和可视化技术
是否原创(转载必填原文地址)
是
项目截图(必填)
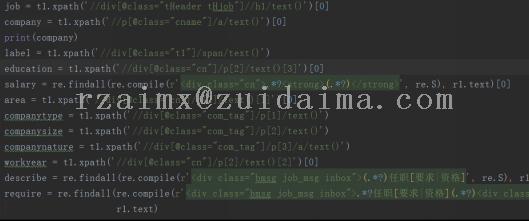
运行截图(必填)
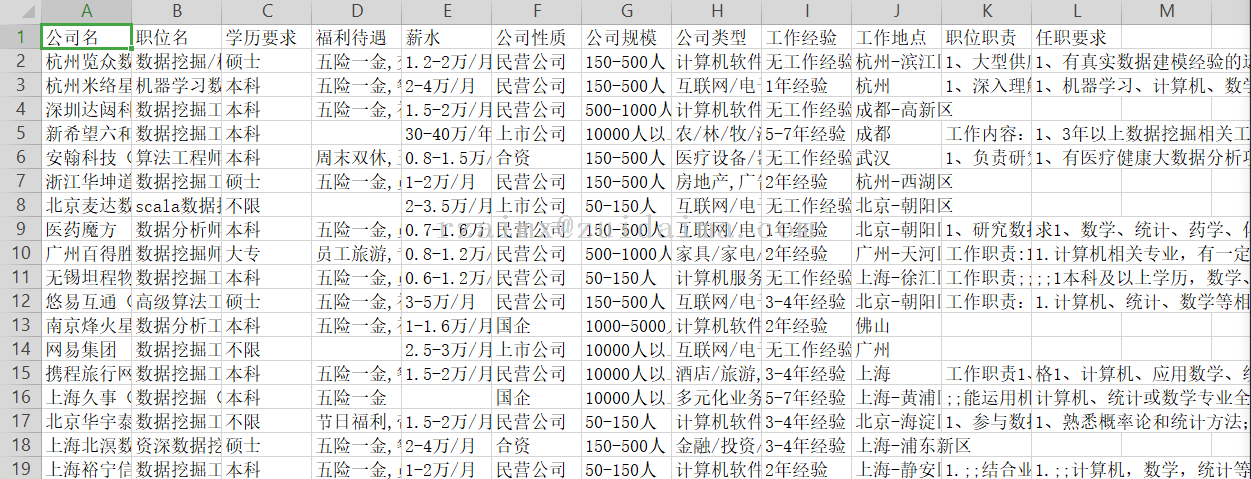

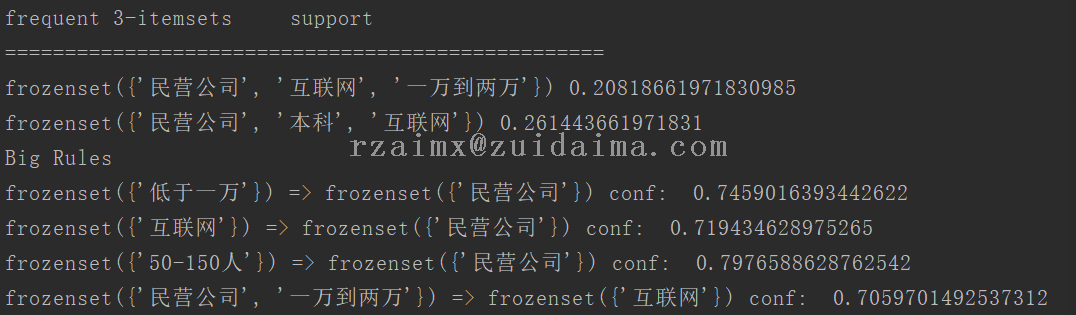
python pi7.py
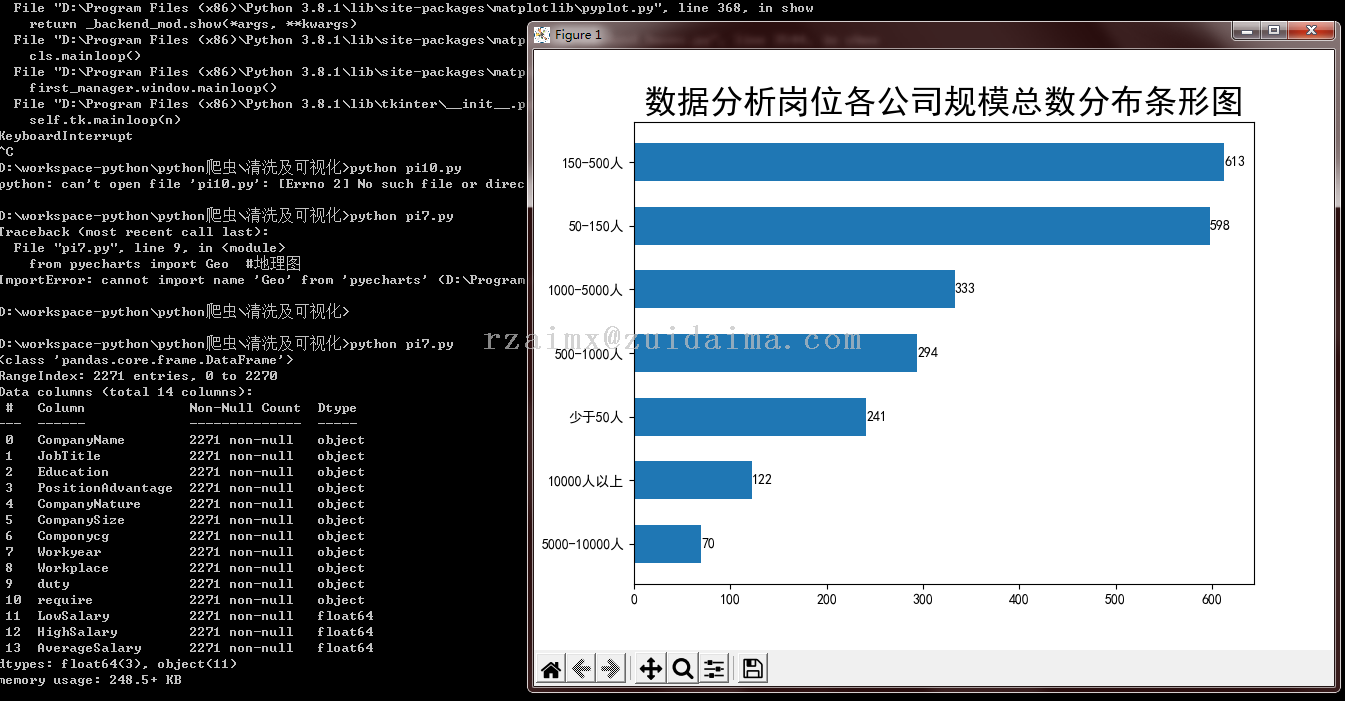
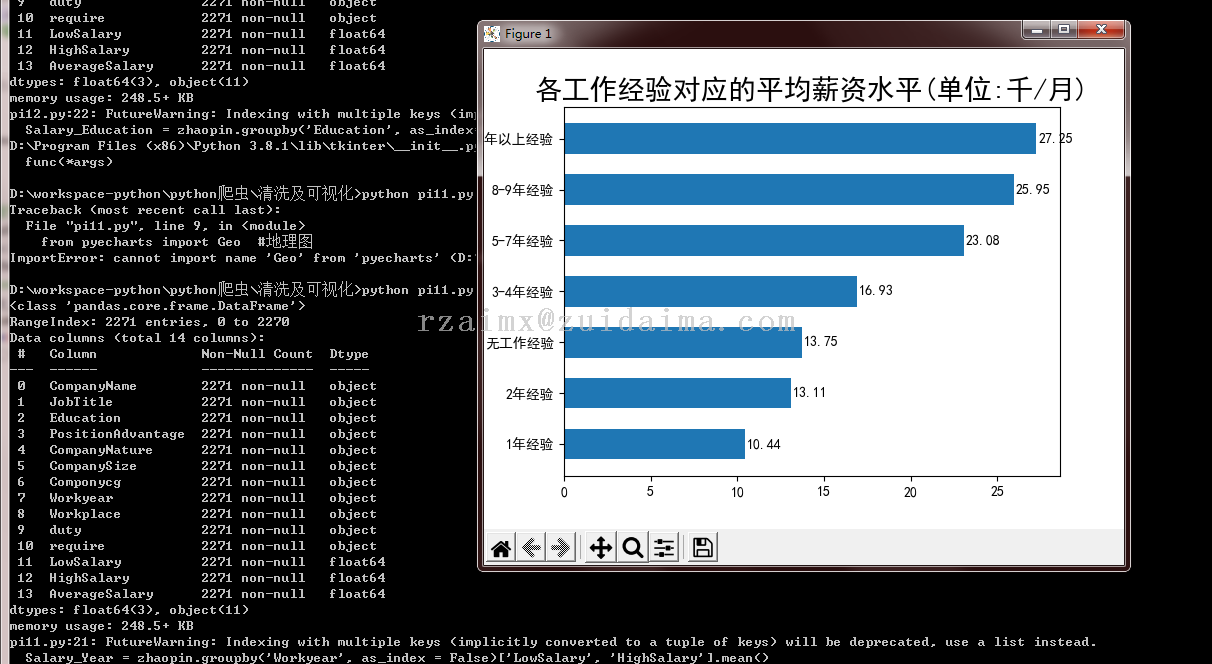
python pi11.py
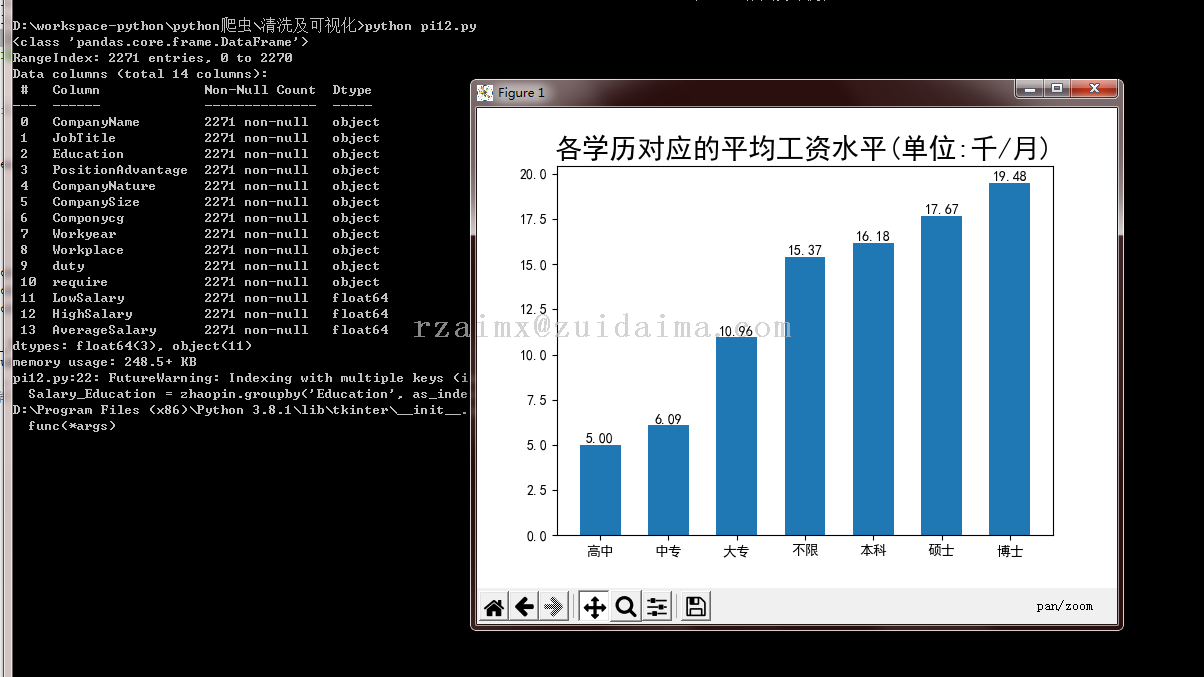
python pi12.py
注意事项
Traceback (most recent call last):
File "pi1.py", line 11, in <module>
from pyecharts import Geo #地理图
ImportError: cannot import name 'Geo' from 'pyecharts' (D:\Program Files (x86)\Python 3.8.1\lib\site-packages\pyecharts\__init__.py)

修改为
from pyecharts.charts import Geo #地理图
最新抓取的解析方式有问题导致没法得到数据,请自行根据html dom格式解析
猜你喜欢
- python前程无忧数据分析师岗位招聘情况爬取
- python+vue实现网站爬虫&数据分析案例
- python+selenium爬虫按关键词搜索实现自动化抓取淘宝商品写入mongodb数据库
- python基本数据统计
- python数据分析--农场与社会保障的关联分析
- python爬取豆瓣电影top250电影数据
- python爬虫抓取并显示新型肺炎数据+分析系统
- 不到200行Python代码爬个小说网站
- python模拟表单登录www.zuidaima.com网站的脚本分享
- python爬虫练手,爬取网站指定小说全部章节,写入txt文件
- python抓取数据并生成2020年新冠疫情省市数据可视化地图
- 经典的多线程捉迷藏过程----python实现
文件名:python爬虫.zip,文件大小:3733.17K
下载
- /
- /python爬虫
- /python爬虫/apridata.csv
- /python爬虫/data.csv
- /python爬虫/datamining.csv
- /python爬虫/test5.py
- /python爬虫/test5_2.py
- /python爬虫/test5_3.py
- /python爬虫/test6.py
- /python爬虫/清洗及可视化
- /python爬虫/清洗及可视化/data.csv
- /python爬虫
 相关代码
最近下载
相关代码
最近下载
1515465193 LV9
2024年12月23日


大神程序员 LV23
2024年6月15日

chenranr LV10
2024年6月13日
zuidama_suche LV1
2024年5月15日
求学的熊猫 LV11
2024年1月21日
tianshi LV7
2024年1月4日
淡凉123456 LV9
2024年1月1日
KAIzx11 LV8
2023年12月24日
yyyy11 LV1
2023年12月16日
Yskysan LV1
2023年12月6日
 最近浏览
最近浏览
1203767407 LV1
4月29日
王东东 LV17
4月16日
1515465193 LV9
2024年12月23日
22280830 LV1
2024年12月9日
咖啡猪
2024年12月2日
暂无贡献等级
xiaoaitx LV8
2024年11月22日
ilovecode521 LV6
2024年8月4日
hychristo
2024年6月27日
暂无贡献等级
chensir_
2024年6月25日
暂无贡献等级
时光海 LV2
2024年6月23日
